Configurazione del file di esportazione
Fase 2 wizard
- Impostazioni di Esportazione
- Tipologia Formato DatiPagina
- Codifica dei Caratteri
- Formato Data
- Precisione Numerica
- Modalità di scrittura
- Delimitatore di Testo
- Configurazioni di Separazione
- Gestione File/Cartella di Output
Impostazioni di Esportazione
Il secondo passaggio del wizard rappresenta il cuore della configurazione tecnica, dove vengono definiti tutti i parametri che determinano come i dati verranno estratti, formattati e salvati nel file CSV finale. Questa sezione è suddivisa in diverse aree tematiche che consentono un controllo granulare su ogni aspetto dell'esportazione:
- Tipologia Formato Dati
- Codifica dei Caratteri
- Formato Data
- Precisione Numerica
- Modalità di scrittura
- Delimitatore di Testo
- Configurazioni di Separazione
- Gestione File/Cartella di Output
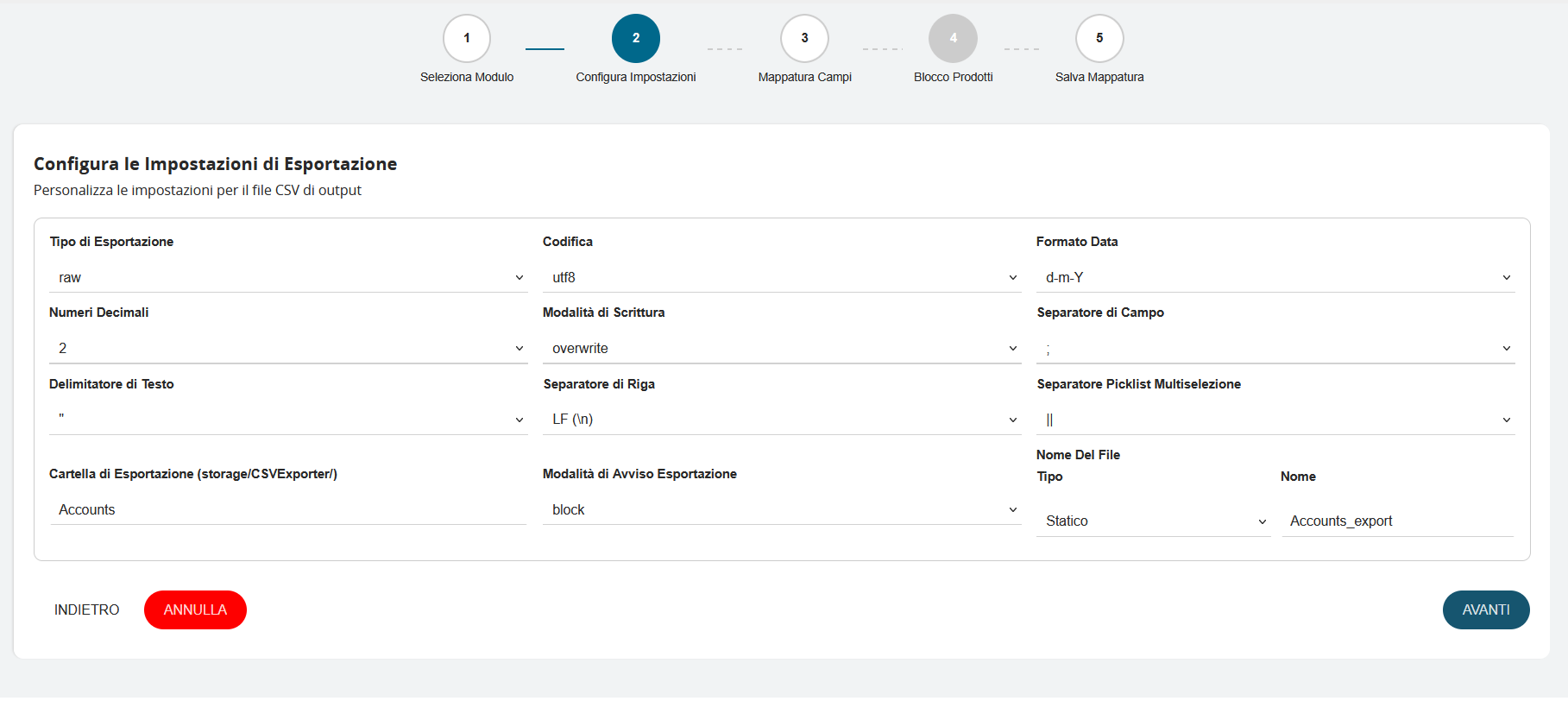
Tipologia Formato DatiPagina
Il campo Tipo di Esportazione offre due modalità distinte per l'estrazione e la formattazione dei dati dal database:
- Raw: tale modalità rappresenta l'approccio più diretto e performante per l'esportazione dei dati. Quando questa opzione è selezionata, il sistema:
- Estrae i dati direttamente dal database senza applicare alcuna elaborazione aggiuntiva
- Mantiene i valori esattamente come sono memorizzati nel sistema
- Preserva la massima fedeltà delle informazioni originali
- Garantisce velocità di esportazione ottimale, particolarmente importante per grandi volumi di dati
- È ideale per analisi tecniche, backup di dati o quando si necessita di preservare l'integrità assoluta delle informazioni - Pretty (Dati Formattati): tale modalità applica invece una serie di elaborazioni per rendere i dati più leggibili e user-friendly:- - Formatta i valori secondo le impostazioni di visualizzazione del CRM
- Converte i codici interni in etichette descrittive
- Applica le regole di formattazione specifiche per ogni tipo di campo
- Traduce i valori delle picklist nei loro equivalenti testuali
- È ottimale per report destinati alla lettura umana o presentazioni
La scelta tra queste due modalità dipende dall'utilizzo finale del file CSV: utilizzare "raw" per elaborazioni tecniche e "pretty" per report e analisi destinate alla consultazione diretta.
Codifica dei Caratteri
Il campo "Codifica" determina il set di caratteri utilizzato per salvare il file CSV, influenzando direttamente la compatibilità e la leggibilità dei dati esportati. Il sistema offre quattro opzioni principali:
- UTF-8 (Unicode Transformation Format - 8 bit): rappresenta lo standard internazionale moderno e la scelta consigliata:
- Supporta tutti i caratteri dell'alfabeto latino, inclusi accenti e caratteri speciali (à, è, ì, ò, ù, ç)
- Gestisce simboli internazionali, caratteri cirillici, greci, arabi e asiatici
- Garantisce la corretta visualizzazione in software moderni (Excel, LibreOffice, Google Sheets)
- Preserva l'integrità di nomi, indirizzi e descrizioni contenenti caratteri accentati - Latin1 (ISO-8859-1): è una codifica europea occidentale più datata:
- Supporta caratteri dell'alfabeto latino con accenti utilizzati in Europa Occidentale
- Compatibile con sistemi legacy e software più vecchi
- Dimensioni file leggermente ridotte rispetto a UTF-8
- Limitata nella gestione di caratteri non europe - ASCII (American Standard Code for Information Interchange): più basilare e limitata:
- Supporta solo caratteri base dell'alfabeto inglese (A-Z, a-z, 0-9)
- Non gestisce accenti, caratteri speciali o simboli internazionali
- Massima compatibilità con sistemi molto vecchi
- Sconsigliata per contenuti italiani o internazionali - Windows-1252 (CP-1252): specifica per sistemi Windows:
- Estensione di ASCII che include caratteri dell'Europa Occidentale
- Compatibilità ottimale con versioni precedenti di Microsoft Excel
- Supporta caratteri accentati e alcuni simboli speciali
- Può causare problemi di visualizzazione su sistemi non Windows
Raccomandazione: Per la maggior parte degli utilizzi, specialmente in contesto italiano, si consiglia UTF-8 per la sua universalità e compatibilità con i software moderni. Utilizzare codifiche alternative solo in casi specifici di compatibilità con sistemi legacy.
Formato Data
Il campo "Formato Data" definisce come le date verranno rappresentate nel file CSV esportato. Il sistema offre cinque formati distinti per adattarsi a diverse esigenze geografiche e di compatibilità software.
Il formato "d-m-Y" (giorno-mese-anno) standardizza la rappresentazione delle date secondo il formato europeo. Questa impostazione assicura coerenza nella visualizzazione delle date e facilita l'elaborazione dei dati da parte di software di analisi o fogli di calcolo configurati per il formato italiano.
Precisione Numerica
Il campo "Numeri Decimali" controlla la precisione numerica di tutti i valori decimali presenti nel file CSV esportato. Il sistema offre cinque livelli di precisione, da 1 a 5 cifre decimali:
Le 2 cifre decimali rappresentano il compromesso ideale per la maggior parte delle esportazioni CSV in ambito aziendale, garantendo dati precisi senza appesantire inutilmente il file o compromettere la leggibilità.
Modalità di scrittura
Il campo "Modalità di Scrittura" determina il comportamento del sistema quando un file CSV con lo stesso nome esiste già nella cartella di destinazione. Il sistema offre due approcci distinti:

- Overwrite (Sovrascrivi): rappresenta l'approccio di sostituzione completa.
Vantaggi:
- Garantisce sempre dati aggiornati e coerenti
- Evita accumulo di file duplicati
- Mantiene un'organizzazione pulita delle cartelle
Svantaggi:
- Perdita permanente della versione precedente
- Impossibilità di recuperare dati storici
Utilizzo ideale: Esportazioni ricorrenti dove serve sempre la versione più recente - Append (Aggiungi): aggiunge i nuovi dati al file esistente, i nuovi record vengono accodati alla fine del file esistente.
Vantaggi:
- Conserva tutti i dati storici
- Crea un archivio cumulativo nel tempo
- Permette analisi di trend e confronti temporali
Svantaggi:
- Possibili duplicazioni di dati
- File di dimensioni crescenti nel tempo
- Necessità di gestire header multipli
- Utilizzo ideale: Log di attività, archivi storici, raccolta dati incrementale
Delimitatore di Testo
Il campo "Delimitatore di Testo" definisce il carattere utilizzato per racchiudere i campi di testo nel file CSV, garantendo la corretta interpretazione dei dati anche quando contengono caratteri speciali.
Il sistema offre tre opzioni principali:

- Virgolette Doppie (") - Consigliato
Le "virgolette doppie" rappresentano lo standard internazionale per i file CSV:
- Esempio: "Mario Rossi","Via Roma, 123","Milano"
- Vantaggi:
- Standard universale riconosciuto da tutti i software
- Protegge campi contenenti virgole (separatore di campo)
- Gestisce correttamente testi con spazi iniziali/finali
- Compatibilità garantita con Excel, LibreOffice, Google Sheets
Utilizzo: Raccomandato per tutte le esportazioni standard - Virgolette Singole (')
Le virgolette singole offrono un'alternativa meno comune:
- Esempio: 'Mario Rossi','Via Roma, 123','Milano'
Vantaggi:
- Utile quando i testi contengono frequentemente virgolette doppie
- Riduce la necessità di escape di caratteri
Svantaggi:
- Meno compatibile con software standard
- Può causare problemi di interpretazione
Utilizzo: Solo in casi specifici o per compatibilità con sistemi particolari - Nessun Delimitatore
L'opzione senza delimitatore elimina qualsiasi carattere di protezione:
- Esempio: Mario Rossi,Via Roma 123,Milano
Vantaggi:
- File più leggeri e compatti
- Elaborazione più veloce
Svantaggi:
- Problemi gravi se i dati contengono il separatore di campo
- Perdita di precisione con spazi iniziali/finali
- Incompatibilità con molti software standard
-
Utilizzo: Sconsigliato, da usare solo se si è certi che i dati non contengano caratteri problematici
Raccomandazione: Utilizzare sempre le virgolette doppie (") per garantire massima compatibilità e protezione dei dati, specialmente in presenza di testi complessi o indirizzi contenenti virgole.
Configurazioni di Separazione
Questa sezione controlla i caratteri utilizzati per strutturare e organizzare i dati nel file CSV, definendo come vengono separati campi, righe e valori multipli.

"Separatore di Campo": definisce il carattere che divide le colonne nel file CSV:
- Virgola (,) - Standard internazionale
- Formato: "Campo1","Campo2","Campo3"
- Compatibilità universale con tutti i software
- Raccomandato per la maggior parte degli utilizzi - Punto e virgola (;) - Standard europeo
- Formato: "Campo1";"Campo2";"Campo3"
- Utilizzato in paesi che usano la virgola come separatore decimale
- Compatibile con impostazioni locali europee di Excel - Tab (\t) - Separatore tabulazione
- Invisibile ma molto efficace per dati complessi
- Ideale quando i testi contengono virgole e punti e virgola
- Ottima leggibilità quando aperto in editor di testo
Separatore di Riga: determina il carattere che indica la fine di ogni record:
- LF (\n) - Line Feed (Consigliato):
- Standard Unix/Linux e macOS moderni
- Compatibilità ottimale con software moderni
- Dimensioni file ridotte - CRLF (\r\n) - Carriage Return + Line Feed
- Standard Windows tradizionale
- Necessario per compatibilità con software Windows legacy
- File leggermente più grandi - CR (\r) - Carriage Return
- Standard Mac classico (pre-OS X)
- Raramente utilizzato nei sistemi moderni
- Mantenuto per compatibilità storica
Separatore Picklist Multiselezione: gestisce campi che possono contenere valori multipli:
- Doppio Pipe (||) - Consigliato
- Esempio: "Valore1||Valore2||Valore3"
- Separatore distintivo che raramente appare nei dati
- Facile da identificare e processare programmaticamente - Punto e virgola (;)
- Esempio: "Valore1;Valore2;Valore3"
- Alternativa più leggibile per utenti finali
- Attenzione a non confondere con il separatore di campo - Virgola (,)
- Esempio: "Valore1,Valore2,Valore3"
- Sconsigliato se la virgola è anche separatore di campo
- Può causare problemi di interpretazione
Esempi Pratici di Utilizzo
Campo multiselezione "Categorie Prodotto":
- Con ||: "Elettronica||Computer||Gaming"
- Con ;: "Elettronica;Computer;Gaming"
- Con ,: "Elettronica,Computer,Gaming" (problematico se , è separatore di campo)
Raccomandazione: Utilizzare virgola (,) come separatore di campo, LF (\n) come separatore di riga, e doppio pipe (||) per le multiselezioni per garantire massima compatibilità e chiarezza nella struttura dati.
Gestione File/Cartella di Output
Questa sezione definisce le impostazioni per la gestione del file di output, inclusa la destinazione, le notifiche e la denominazione del file CSV finale.

- Cartella di Esportazione: mostra il percorso di destinazione dove verranno salvati i file CSV:
- Percorso base: `storage/CSVExporter/`
- Struttura: Il sistema crea automaticamente una sottocartella per ogni modulo
- Esempio: `storage/CSVExporter/Accounts/` per il modulo Account - Modalità di Avviso Esportazione: controlla come l'utente viene informato al completamento dell'operazione tramite:
- Block (Blocco): avviso che blocca l'interfaccia utente
- Alert (Avviso): mostra una notifica non bloccante - Nome Del File. La configurazione del nome file comprende due elementi fondamentali che determinano come verrà denominato il file CSV finale:
- Tipo: Il sistema offre due approcci per la creazione del nome file. La modalità "Statico" mantiene sempre lo stesso nome per ogni esportazione, garantendo prevedibilità e facilità di identificazione, ma comporta il rischio di sovrascrivere versioni precedenti. La modalità "Dinamico" genera automaticamente nomi univoci utilizzando criteri variabili come timestamp o numeri incrementali, preservando così lo storico delle esportazioni ma creando nomi meno prevedibili.- Nome: definisce la base identificativa del file CSV. Nell'esempio mostrato, `Accounts_export` diventerà automaticamente `Accounts_export.csv` una volta completata l'esportazione. È fondamentale utilizzare nomi descrittivi che riflettano il contenuto del file, evitando caratteri speciali o spazi che potrebbero causare problemi di compatibilità con diversi sistemi operativi.
Esempi di denominazione efficace includono `Clienti_attivi_2025`, `Ordini_mensili_marzo` o `Fatture_pagate_2025`, che forniscono informazioni immediate sul contenuto e il periodo di riferimento dei dati esportati.